
An enlightening Q&A with our NLP experts
| Q: | How many words does an average English speaker know? |
| A: | A study in 1986, estimated the size of the average person’s vocabulary as developing from roughly 300 words at two years old, through 5,000 words at five years old, to some 12,000 words at the age of 12, while a graduate might have a vocabulary nearly twice as large (23,000 words) [1]. |
| Q: | But wait a minute, how many words are there in the English language? |
| A: | Well, a lot more, the Global Language Monitor says that the number of words in English is 1,025,109.8 words [2], and it changes and evolves since language is not static: we are creative and we are always creating more words. |
| Q: | Do we all know the same words? |
| A: | No, of course not: people with different backgrounds have different vocabularies, but of course there are many common words. |
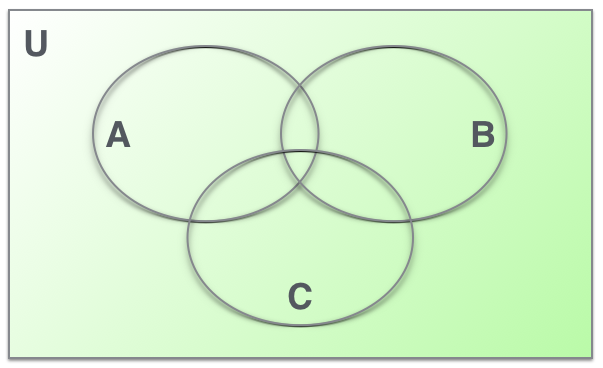
A represents the words that you know. B represents the words that your best friend knows and C represents the words that your boss knows. U represents the entire number of words in the language that you all three speak.
| Q: | I don’t understand… how are we able to communicate if we don’t share all the linguistic units? |
| A: | People are intelligent, we are capable of generalizing words that are similar to each other. For example, we know that the word “dog” and the word “cat” are going to behave in a similar way within a sentence, semantically as well as syntactically. If we don’t know the word “cat”, but we know the word “dog”, we are still able to predict the linguistic behaviour of “cat” thanks to our capacity to extract linguistic patterns (fed with our linguistic knowledge about “dog” and many other units). |
 |
 |
| Q: | Can you elaborate a bit more? |
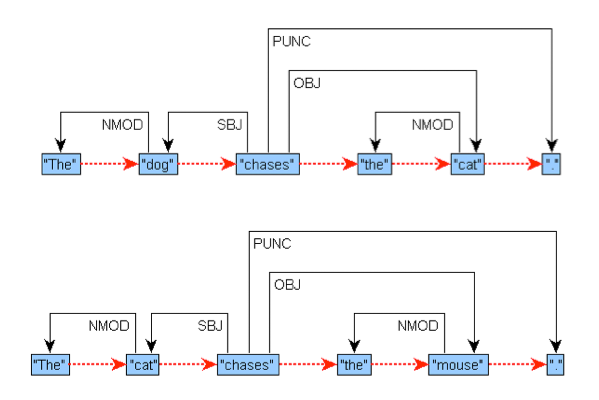
| A: | Of course. Imagine that we have heard the sentence “The dog chases the cat” several times, but we haven’t ever heard the sentence “The cat chases the mouse”. As soon as we hear it, we infer that cats do some things similarly to dogs: at least they also chase. But we know even more: we also know that “cat” have the same syntactic behaviour in the latter sentence as “dog” in the former sentence, and we also know that “cat”, in the first sentence, has the same role as “mouse” in the second sentence, but… what is a “mouse”? Oh! We don’t know yet, but as the pattern detection and the learning process goes on, we will know soon. People are smart, people can generate new knowledge by just listening or reading: we all make a lot of assumptions that are usually correct. |
| Q: | Is it possible to model that with a machine? Sounds like magic. |
| A: | No, it is not magic. We have artificial intelligence and machine learning to get it. |
| Q: | What is machine learning and what is its application in all of this? |
| A: | Machine learning is a field in computer science that constructs algorithms that can learn from and make predictions on new data. So, imagine that we want to do a syntactic analyzer that automatically analyzes sentences. In order to do so, first, expert linguists annotate a lot of different sentences with part-of-speech tagging and syntactic relations. Thus, in “The dog chases the cat”, the annotation establishes that “dog” is a noun, that “cat” is a noun too, and that “chases” is a verb. This smart linguist will also annotate that “dog” is the subject of “chases” and that “cat” is the object of it. The machine learns from this information and, when you prompt the machine to parse the sentence “The cat chases the mouse”, it knows what to do because it makes generalizations and finds patterns. Thus, it assigns similarities between this new sentence and the sentences already known. The concrete job, then, is very similar to the one made by humans. |
| Q: | Wow, that sounds like intelligence. Is it perfect? Are we sure that the output is always perfect? |
| A: | Oh no, of course not. For instance, in English, state-of-the-art systems get around 90% of correct predictions when it comes to syntactic relations such as subject or object (there are around 40 different relations to predict). But think about it, people also make mistakes, we also generalize and we can only learn more when we have more information, but we also tend to forget. The machines work the same way; two of the differences with humans are that (i) machines tend to forget less about what they learn, but (ii) they only learn what is passed to them, whereas humans have access to a wider range of information when trying to understand an utterance (knowledge about the interlocutor, about the current global context, a lot of experience in communication, etc.). |
| Q: | What does all of this have to do with MULTISENSOR? |
| A: | MULTISENSOR’s multilingual automatic text analysis system implements the same machine learning as I described before and outputs a comprehensible representation (similar to the Figures above) for sentences that are used to extract very useful information. We have expert linguists that make annotations in complex sentences, and we have machine learning experts that know how to design and write this intelligent systems towards natural language understanding. |
Photo Credit:
The images of the cat, dog and mouse have been taken from Pixabay.com and have been published under CC0 Public Domain.
Sources:
- The Guardian, 12 August 1986, cited in David Crystal, The English Language, 2002, p46
- http://www.languagemonitor.com/number-of-words/number-of-words-in-the-english-language-1008879/
