4. November 2016
Structuring the web!

How to extract relevant information from multimedia data in different languages?
Why does the web even need structuring?
When Tim Berners-Lee “founded” the modern internet in 1999, he did so by setting up principles for structuring data and hence laid the foundation of the Semantic Web. But since then, a lot has changed and the web has grown enormously. And it still does every day. This evolution is a huge challenge for the machines in terms of processing all of this to extract and provide relevant information to the users.
To solve this issue, an initiative called the Web of Data appeared 10 years ago. The objective of this initiative is to transform the digital information into structured data. by organising it using a logical structure of information (i.e. specific data models). This structure is based on ontologies which are logical models to represent objects and abstract representations of the world (concepts) allowing for an easier processing and comprehension level by machines.
For example, a page web is considered as a document that has an author, a date of publication, a title, the body content. This document can also contain several sections. Then, this structure of information facilitates the data processing and permits a more relevant access to the information by the humans and the machines.
So the Web of Data can be considered as a huge knowledge base that accessible from any point of the earth. This opens many potentials to exploit the digital content on the Web in a smart way.
How exactly does the structuring work?

The structuring process is a big challenge. By taking advantage of the Web of Data, several approaches are possible:
- Manual annotation: before publishing the web content, the author has to manually create the metadata to structure the content. Some web editors can assist the author to add the metadata to structure the content.
- CMS approach: the Content Management Systems are editors of content which permits to integrate the structure of the documents and then produce automatically the associated metadata. For example, Drupal can be used as a web application to create a blog and publish the posts. In this case, all the metadata related to the post such as the author, the date, the content, tags, etc. are automatically created.
- Automatic structuring: the last approach consists to process the content of the document and process it in order to detect automatically some relevant information and transform it as a structured block of the document. For example, the text of the content can be analysed by the machine to detect the names of the locations, person, or organisations.
In MULTISENSOR, we’ve applied the second and the third approach.
→ First, the metadata of the news pages are extracted and used to describe the context of the document.
→ Secondly, the content is analysed in order to extract the relevant “knowledge” and to store the extracted “knowledge” in semantic repositories (triple store, like GraphDB) to enable advanced functionalities on this content such as:
- Semantic search,
- Validation of the coherency of the content,
- Inference of new facts based on reasoning techniques,
- And an advanced way to browse the content using the semantic relations that exists between the data.
How does one extract knowledge?
Automatically processing the web content and detecting the structure is not an easy task. Very specific algorithms have to be developed in order to produce an accurate detection of the structure of the documents. Most approaches rely on techniques of artificial intelligence, using machine learning, natural language processing (linguistic analysis of the texts), image processing, etc.
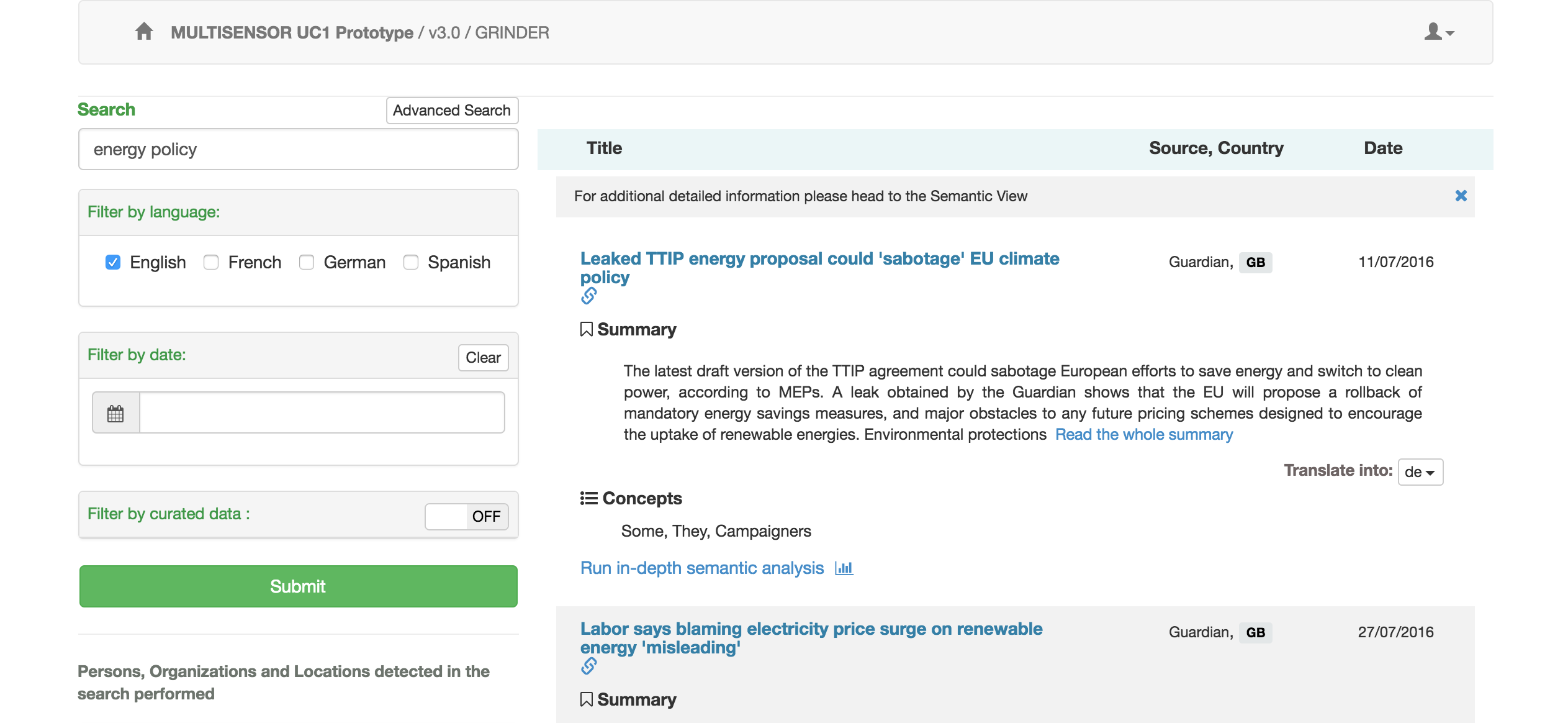
Screenshot of the User Interface of the MULTISENSOR Use Case 1
The MULTISENSOR platform is an integration platform to process huge quantities of heterogeneous contents. The sources of information that are processed are web pages, videos and social media items. Besides the diversity of these items in terms of format and content, all items can be found in several languages, too. For all these modalities, different services can be used to automatically process and detect “the knowledge” within:
- Textual analysis
- Named Entity Recognition: Recognising the names of the known person, locations or organisation from the text
- Concept extraction: Detects the main concepts from the text
- Summarisation: Provide an automated summary of the article
- Classification: Detecting the topic of the content
- Content extraction: Interpreting the metadata provided by the author of the document
- Multimedia analysis
- Audio and Speech recognition: this service extracts the audio track of the video and recognises the human voice. The detected content is recognised as a speech and transformed to text.
- Concept and Event detection: from the video sequences (images) or the pictures, some graphical patterns are recognised and associated with specific concepts. For example, if some people appear in the picture, the concept human is associated to the content.
- The multilingual analysis
- Machine translation: this service provides a translation of any piece of text (article, summary, etc.) in several languages. In MultiSensor, five languages are available (English, French, Spanish, German and Bulgarian). English is used as a transmitter language between the originals and the other languages.
- NER and concepts: as explained previously, these two services extract the Named Entities and the concepts, and can be applied to texts with different languages. In fact, the concept in one language will not necessarily have the same label in another language.
The textual analysis of web content is the core data processing feature in the MULTISENSOR platform. Integrating so many technologies to structure digital content, MULTISENSOR provides a powerful solution to contribute to a more structured web, all in line with the idea of the Web of Data.
Photo Credit: The two images in this article taken from Pixabay.com and have been published under CC0 Public Domain.
Cover image: Ethernet
Second Image: Lego Wally
