
Spatial Context Evaluation Framework
Framework description
Aim of this framework is the investigation of the behavior and the resulting performance of different spatial context exploitation techniques for different combinations of classifiers and low-level features. The framework has been developed in collaboration with the ISWeb - Information Systems and Semantic Web Research Group at the Institute for Computer Science, University of Koblenz-Landau, within the EU-funded K-Space research project.
In this work, two approaches making use of spatial knowledge for semantic image analysis are comparatively evaluated. The first one is based on a Genetic Algorithm (GA), which is employed in order to decide upon the optimal semantic image interpretation by treating semantic image analysis as a global optimization problem. On the other hand, the second method follows a Binary Integer Programming (BIP) technique for estimating the optimal solution. Initially, the examined image is segmented and two individual sets of low-level descriptors are extracted for every resulting segment. In parallel to this procedure, for every pair of image regions a corresponding set of fuzzy directional spatial relations are estimated. Then, the computed descriptors are provided as input to two different classifiers, namely a Support Vector Machine (SVM)- and a Maximum Likelihood (ML)-based one, in order to associate every region with a predefined high-level semantic concept based solely on visual information. The latter is used for denoting a real-world object that can be present in the examined image. Consequently, the two aforementioned spatial context techniques, which perform on top of the initial classification results and which make use of the available spatial knowledge, are applied in order to estimate an optimal region-concept assignment. The reported experimental results demonstrate the improvements attained using spatial context in a number of different image analysis schemes.
Data
The image set utilized in this work was provided by Alinari 24 ORE (http://www.alinari.com, info: euproject-2@alinari.it). The dataset includes: a) the utilized image set, b) the image segmentation masks, c) region-level manual image annotation, d) the extracted low-level features, e) the computed fuzzy directional spatial relations, and f) the region classification results based solely on visual information.
Download the developed framework.
Note: The dataset is publicly available for non-commercial use. Please refer to [Papadopoulos et al., Proc. WIAMIS'09, London, UK] if this dataset is used for experimentation in publications.
Indicative region-concept association results
|
|
Input image |
Region classification |
Spatial context |
|
a) |
|
|
|
|
b) |
|
|
|
|
c) |
|
|
|
|
d) |
|
|
|
|
e) |
|
|
|
|
f) |
|
|
|

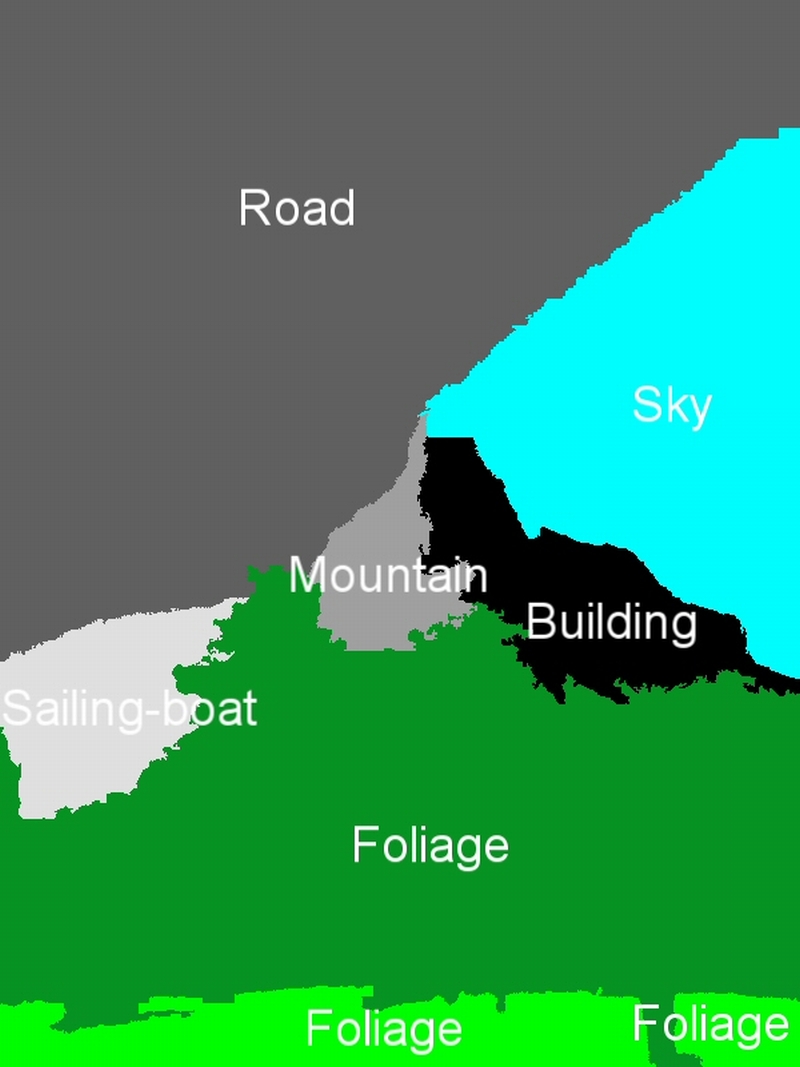


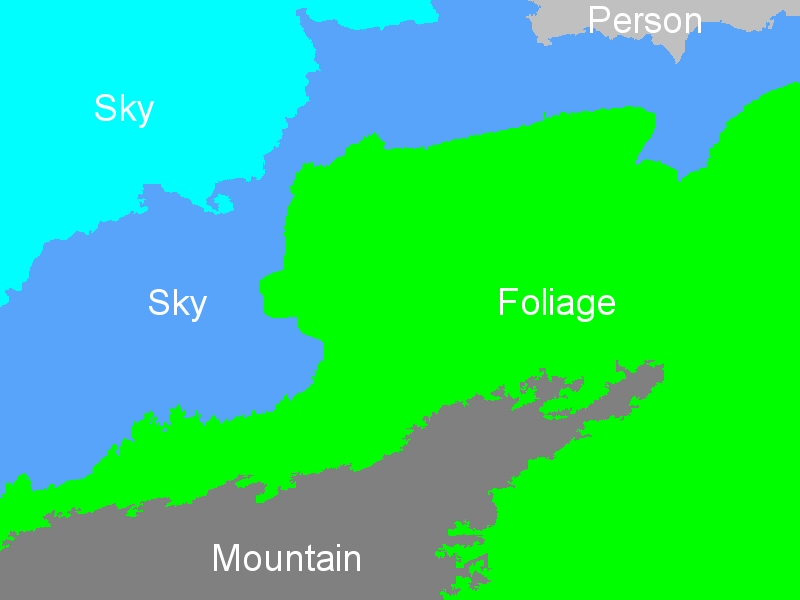
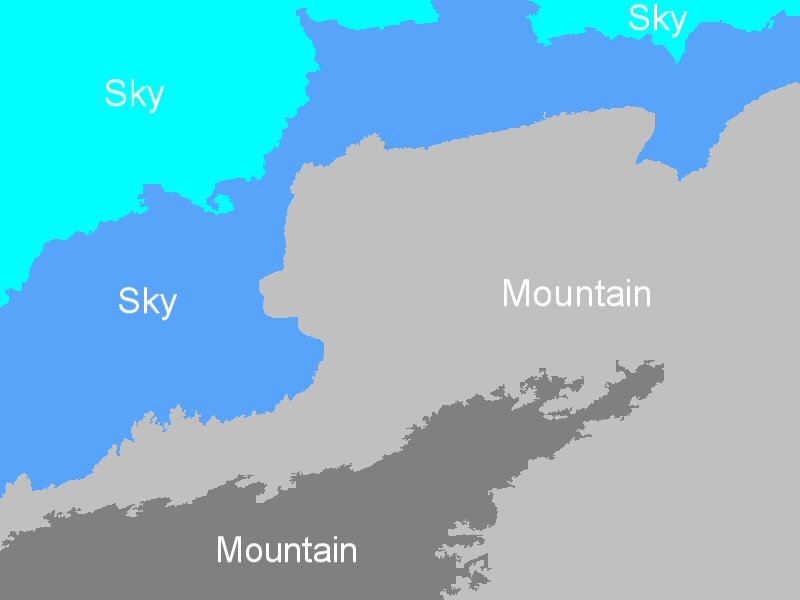

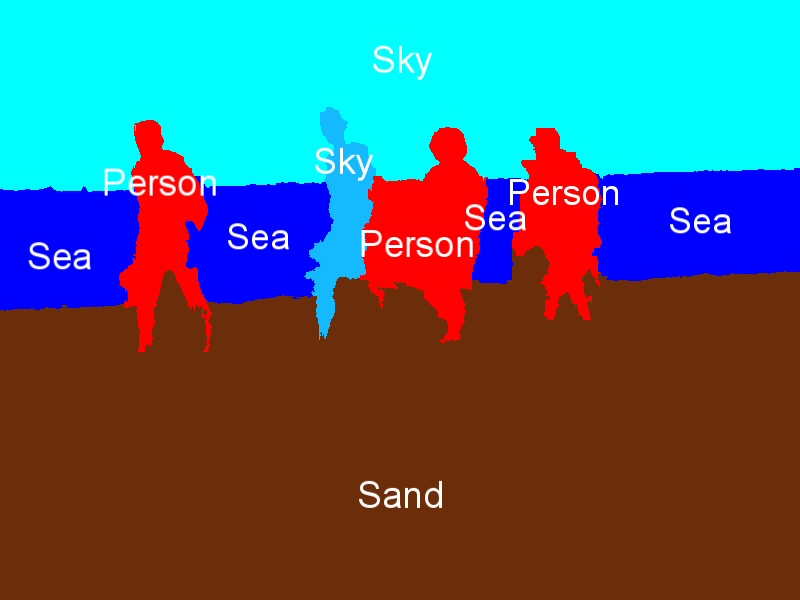
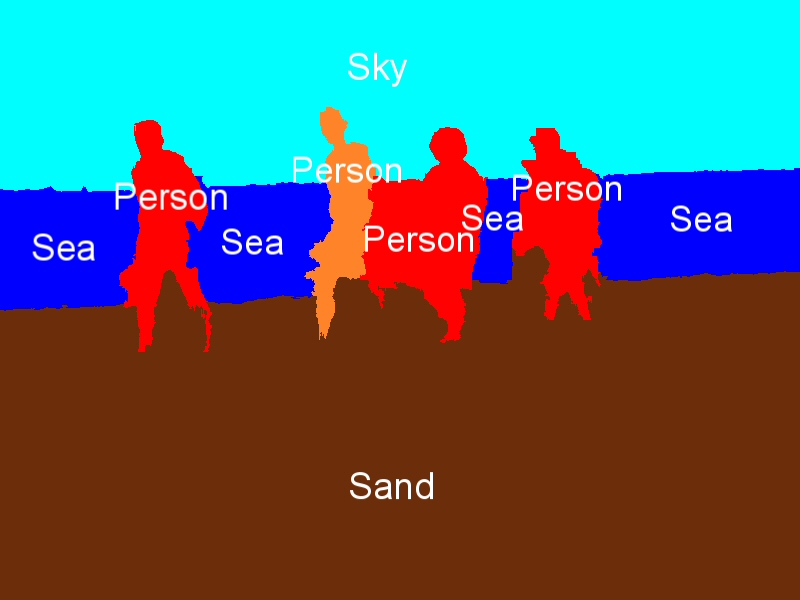




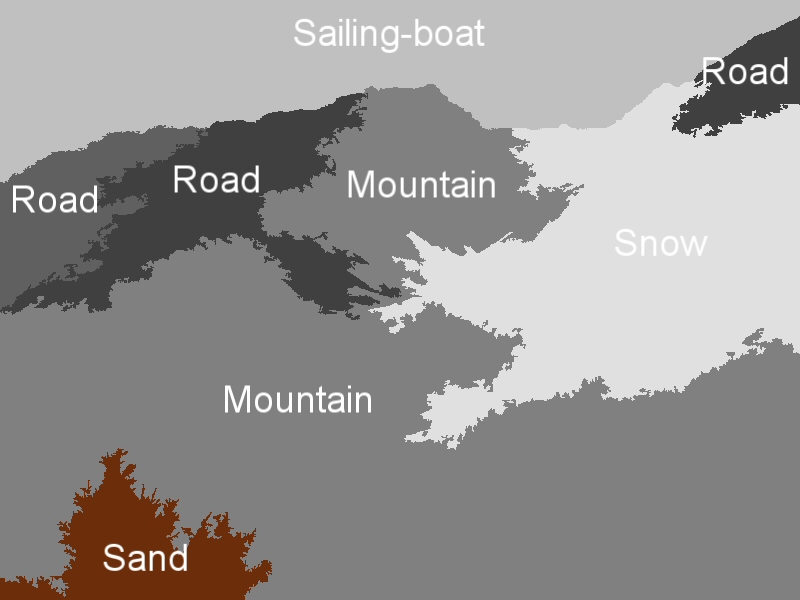
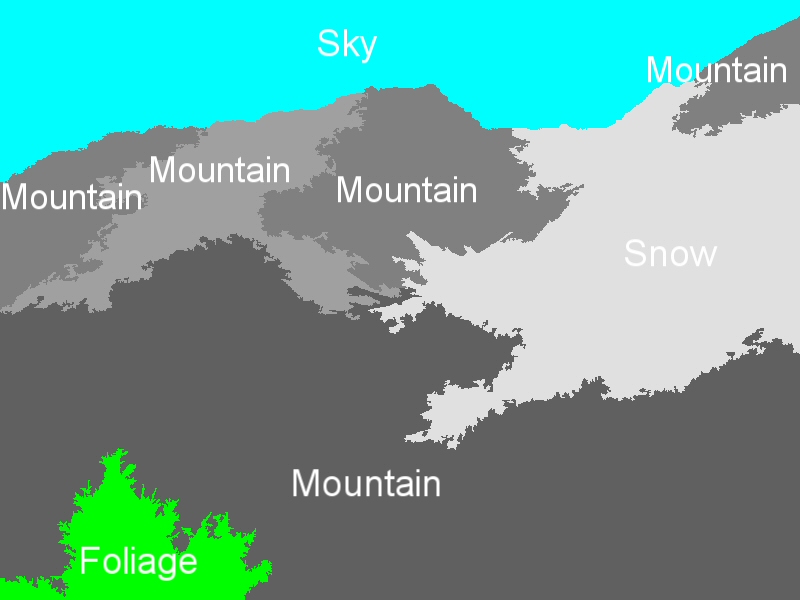

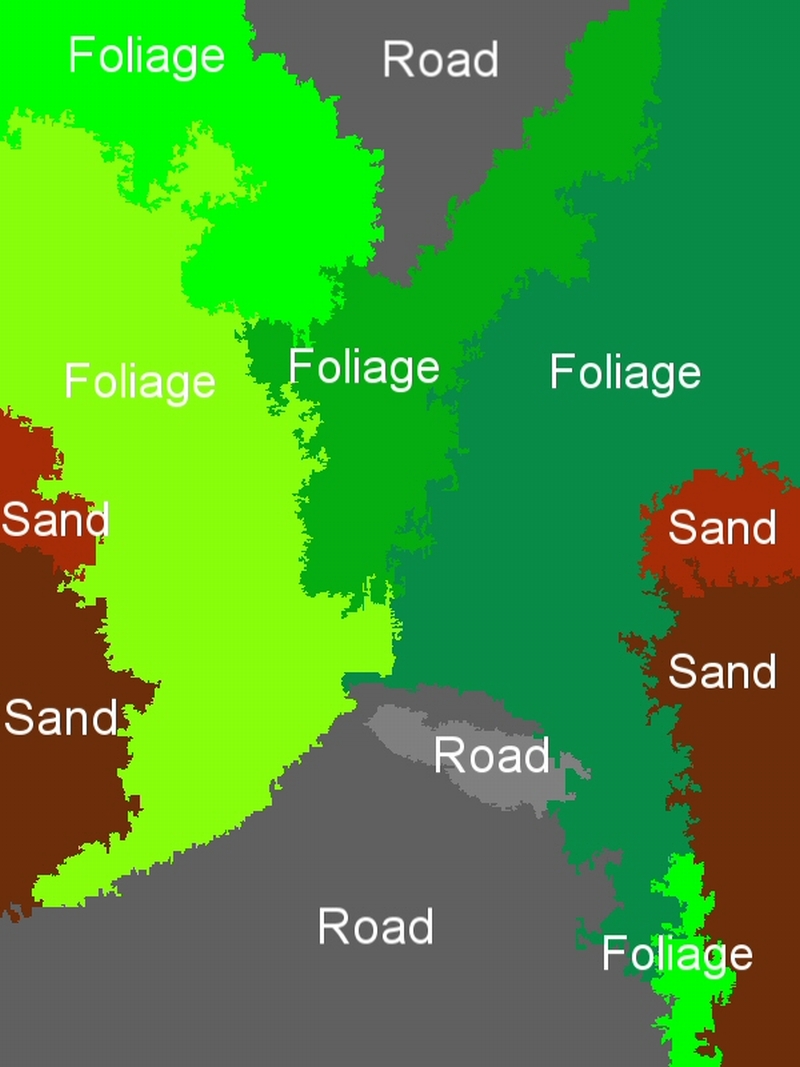

Indicative region-concept association results for the following feature-classifier-spatial context exploitation technique combinations: a) MPEG-7-ML-BIP, b) MPEG-7-ML-GA, c) MPEG-7-SVM-BIP, d) MPEG-7-SVM-GA, e) wavelet-ML-BIP, and f) wavelet-ML-GA.
Concept detection accuracy
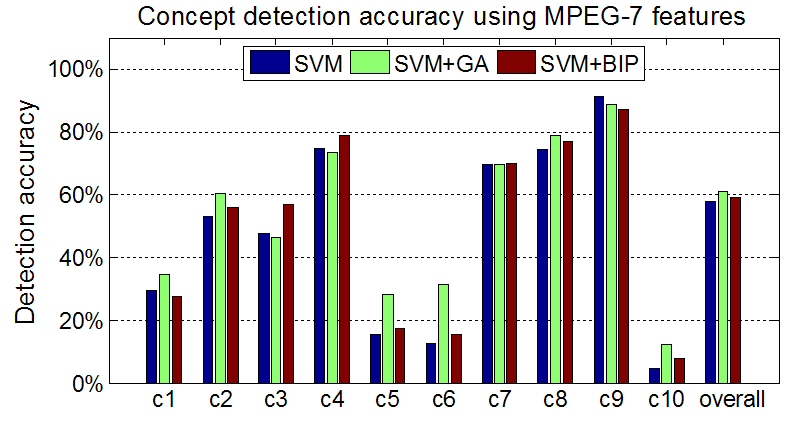
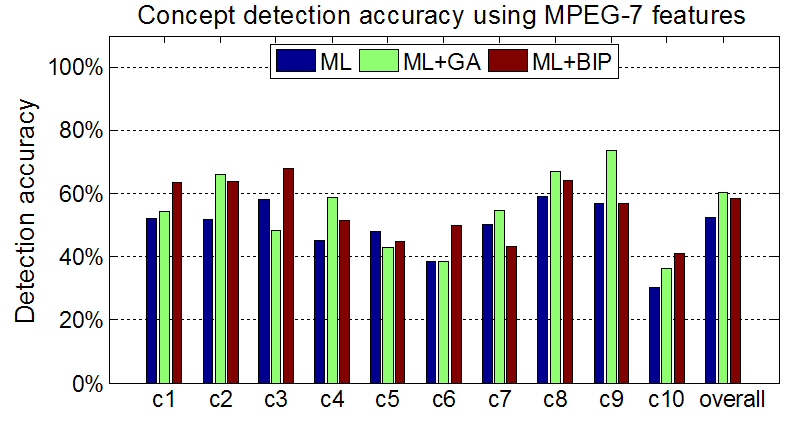
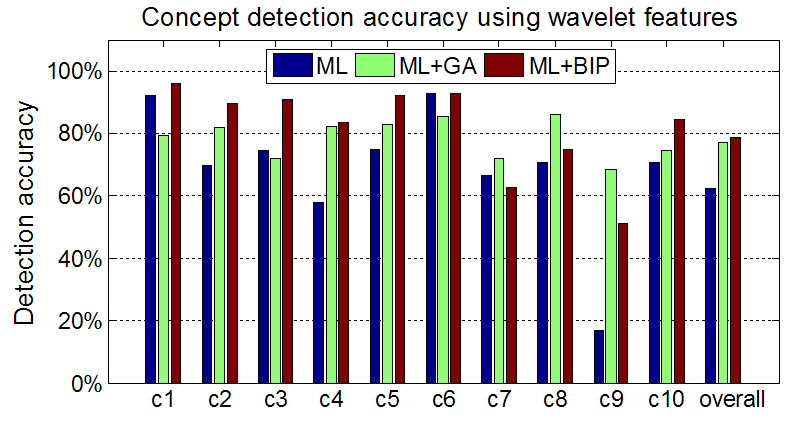
Concept detection accuracy (c1: Building, c2: Foliage, c3: Mountain, c4: Person, c5: Road, c6: Sailing-boat, c7: Sand, c8: Sea, c9: Sky and c10: Snow).
Publications
G. Th.
Papadopoulos, C. Saathoff, M. Grzegorzek, V. Mezaris, I. Kompatsiaris, S. Staab
and M. G. Strintzis, "Comparative Evaluation of Spatial Context Techniques
for Semantic Image Analysis", 10th International Workshop on Image
Analysis for Multimedia Interactive Services (WIAMIS 2009), London, UK,
accepted for publication. 