
MKLab will present their work on Learning to Detect Misleading Content on Twitter and YouTube to ICMR 2017
MKLab have been working for some time now on the problems of fake news and of misinformation in social media. Our work has recently led to some important achievements: we developed a very effective machine learning-based algorithm for automatically deciding whether a tweet is credible, i.e. whether it accurately reflects the event to which it refers.
Training this algorithm became possible by creating a large corpus of past tweets that have been annotated as “fake” or “real”. To help other researchers and practitioners working in the area, we decided to publish this dataset, which we call Image Verification Corpus (since we initially focused only on tweets that contained images), on GitHub. Generating the dataset was a challenge on its own and in addition to expending large manual effort, we needed to employ smart heuristics based on near-duplicate image detection and text mining to considerably expand it and to make sure that the annotations were of high quality.
With this dataset in place, we set out to train a machine learning algorithm in order to tell credible tweets from misleading ones. A first challenge we faced in our effort to do this was the extraction of appropriate features for the task. Since we were not the first to tackle this problem, we could start from an initial set of features that had been previously used in the literature, and pertained to the text characteristics of tweets, e.g. the number of capital letters or the use of exclamation marks. But we soon realized that this set could be further enriched with more features, for instance the use of sentiment-carrying words as well as text quality features, such as the Flesch Reading Ease score. In addition, tweets carry important context with them. For instance, several of them contain links to websites, which can themselves act as indicators of information credibility. Hence, we made sure to design additional features that capture such content aspects.
But even with the extended set of features, we quickly found out that when relying on off-the-shelf machine learning algorithms (such as Support Vector Machines, Decision Trees and Random Forests), the achieved classification accuracy was limited when testing the algorithm on tweets that were associated with an “unseen” event, possibly quite different from the ones found in the training set. To this end, we engineered a sophisticated semi-supervised learning scheme, where two independent classifiers make predictions on the unseen tweets, and then the predictions that agree with each other are used to retrain the independent classifiers. We found that this technique in tandem with using ensemble learning when training the independent classifiers led to considerable gains in the classification accuracy of tweets that were posted in the context of unseen events.
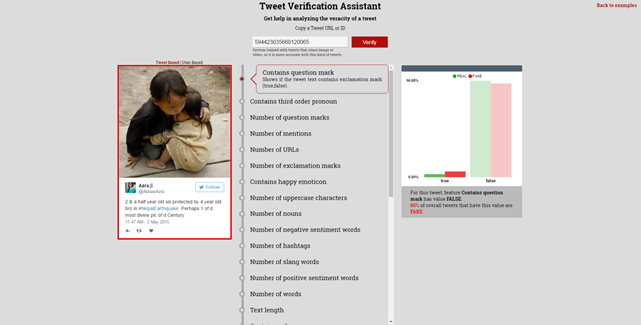
In the end, we were also interested in presenting our results to end users, e.g. journalists and news editors. To this end, we built the Tweet Verification Assistant (cf. figure), a web-based user interface where the user can enter a tweet id and obtain a decision of whether the tweet is credible or not along with a detailed analysis of how its features are similar or different compared to “real” and “fake” tweets of our corpus.
Moving beyond Twitter, we were also interested in applying a similar approach to verify YouTube videos. In that case, we could extract similar features from YouTube metadata (e.g. popularity of channel posting the video, title and text description of video, etc.) as well as from the comments that users post in relation to a video. After a careful evaluation on a small but representative sample of verified and debunked YouTube videos that we used as ground truth, we demonstrated that our approach could lead to high detection rates of fake videos. We also found out that comment-based features are not reliable in the first minutes after a video is posted, and that fusing comment- and metadata-based features was a hard task.
We expect that the area of social media content verification using carefully engineered content- and context-based features in tandem with machine learning algorithms offers an exciting and very challenging research playground for testing data-driven and multimedia mining approaches, and it holds promise as an effective means for ensuring more accurate news reporting and information spread in media sharing platforms in the future.
We are going to present our social media verification research in the upcoming International Conference on Multimedia Retrieval that will take place in Bucharest, June 6-9, 2017.
More technical details are available in our papers:
C. Boididou, S. Papadopoulos, L. Apostolidis, Y. Kompatsiaris (2017). “Learning to Detect Misleading Content on Twitter.” In Proceedings of ICMR 2017
O. Papadopoulou, M. Zampoglou, S. Papadopoulos, Y. Kompatsiaris (2017). “Web Video Verification using Contextual Cues.” In Proceedings of MFSec ICMR 2017 workshop
Our research has been supported by two EU-funded projects focusing on social media verification, REVEAL and InVID.