CERTH in REVEAL - Social Media Verification
A 5-minute Guide to the Project Outcomes by the MKLab Team
A 5-minute Guide to the Project Outcomes by the MKLab Team
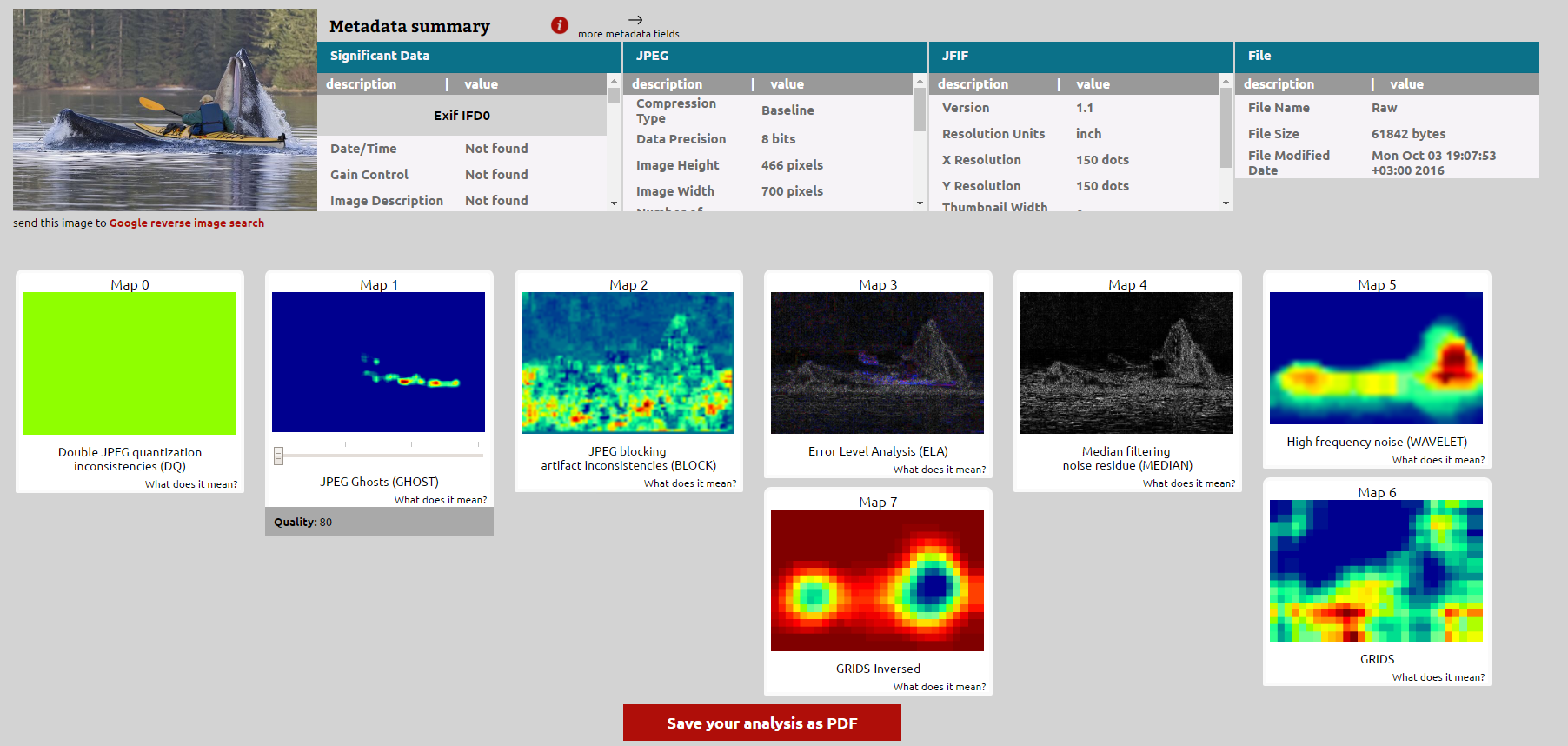
This is a web-based user interface that can support the verification of an arbitrary image found on the web or uploaded by the user. Once the user clicks “Verify”, the system presents the results of seven forensics analysis algorithms (six from the state-of- the-art and one developed within REVEAL). In addition, it presents in a concise way all Exif metadata found in the image, and automatically generates a link to perform reverse image search (with the use of the respective Google service). Finally, the system offers the possibility of exporting the results of the analysis in a PDF document.
DemoDatasets: Wild Web Tampered Images, DW Image Forensics
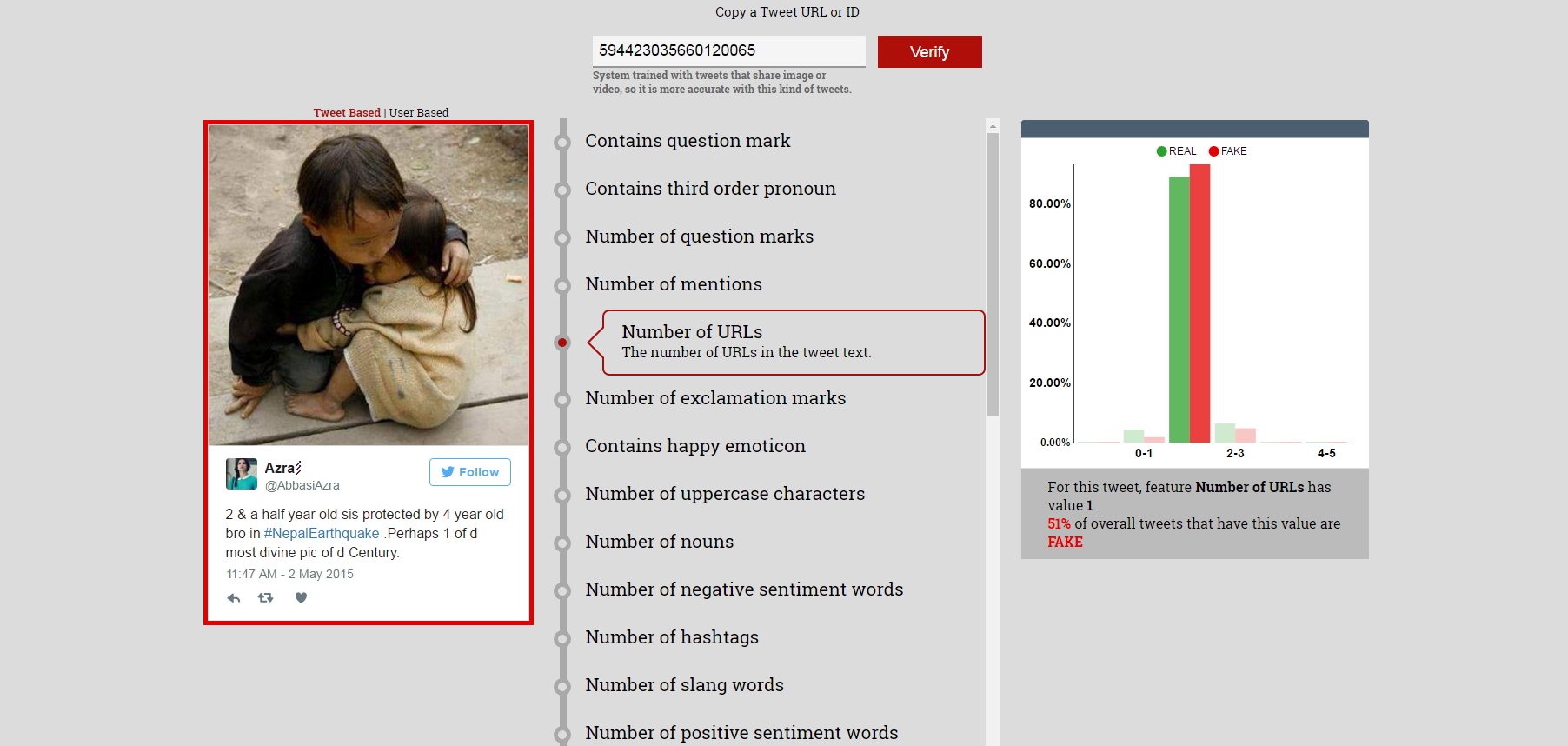
This is a web-based user interface that can support the verification of an arbitrary tweet. Once the user clicks “Verify”, the system presents a prediction of whether the tweet should be considered fake(misleading) or real (trustworthy) using red and green color respectively, and visualizes a number of extracted features that are typically associated with fake and real tweets. The implementation of the algorithm that produces these results has been open sourced.
DemoExtras: Verification Corpus, Benchmarking
This is a web-based user interface that demonstrates the potential of modern computer vision technology to automatically identify images with disturbing and potentially traumatizing content. The implementation of the classification algorithm is based on a state-of- the-art approach that uses Deep Convolutional Neural Network features and was trained on a dataset collected and annotated by CERTH researchers for this purpose.
Demo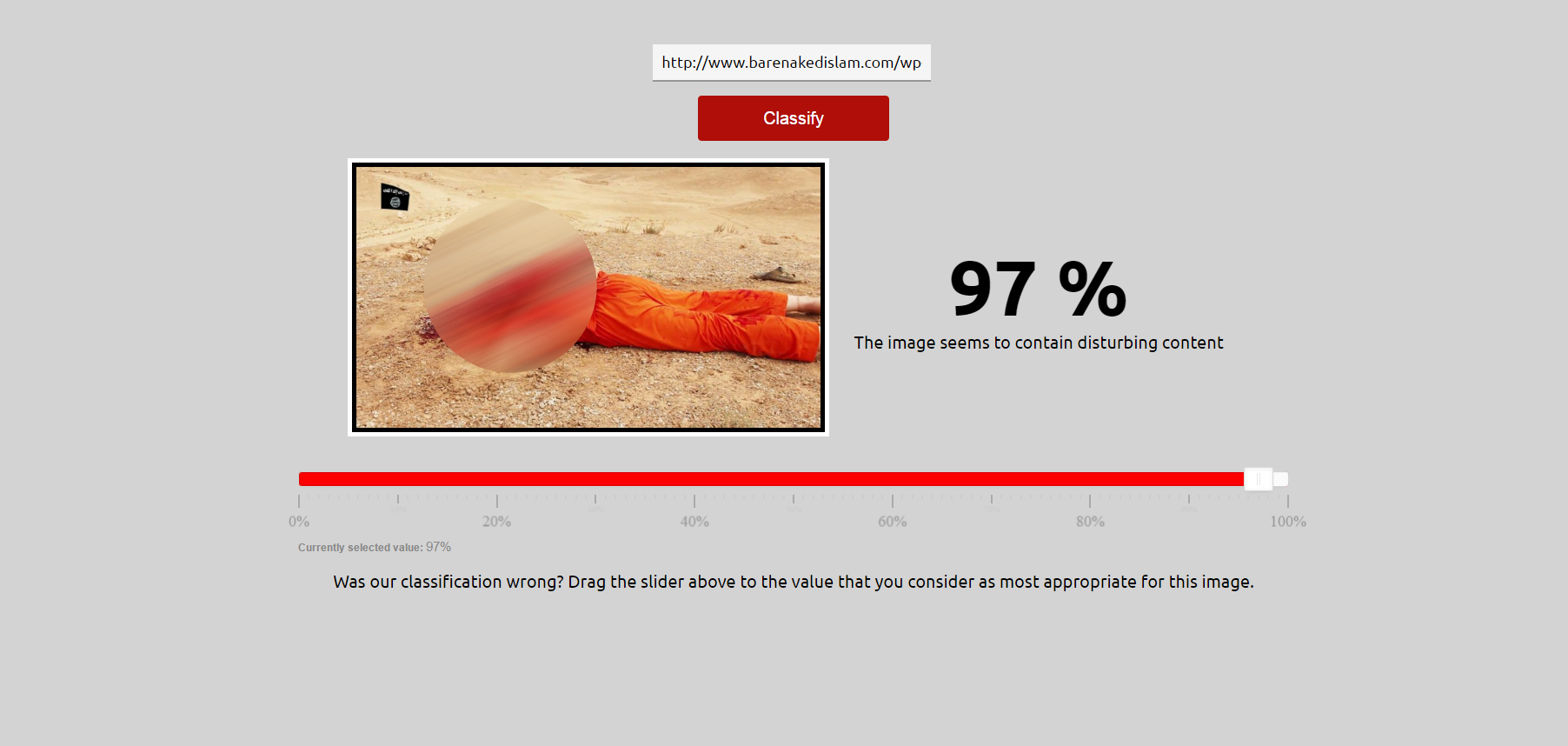
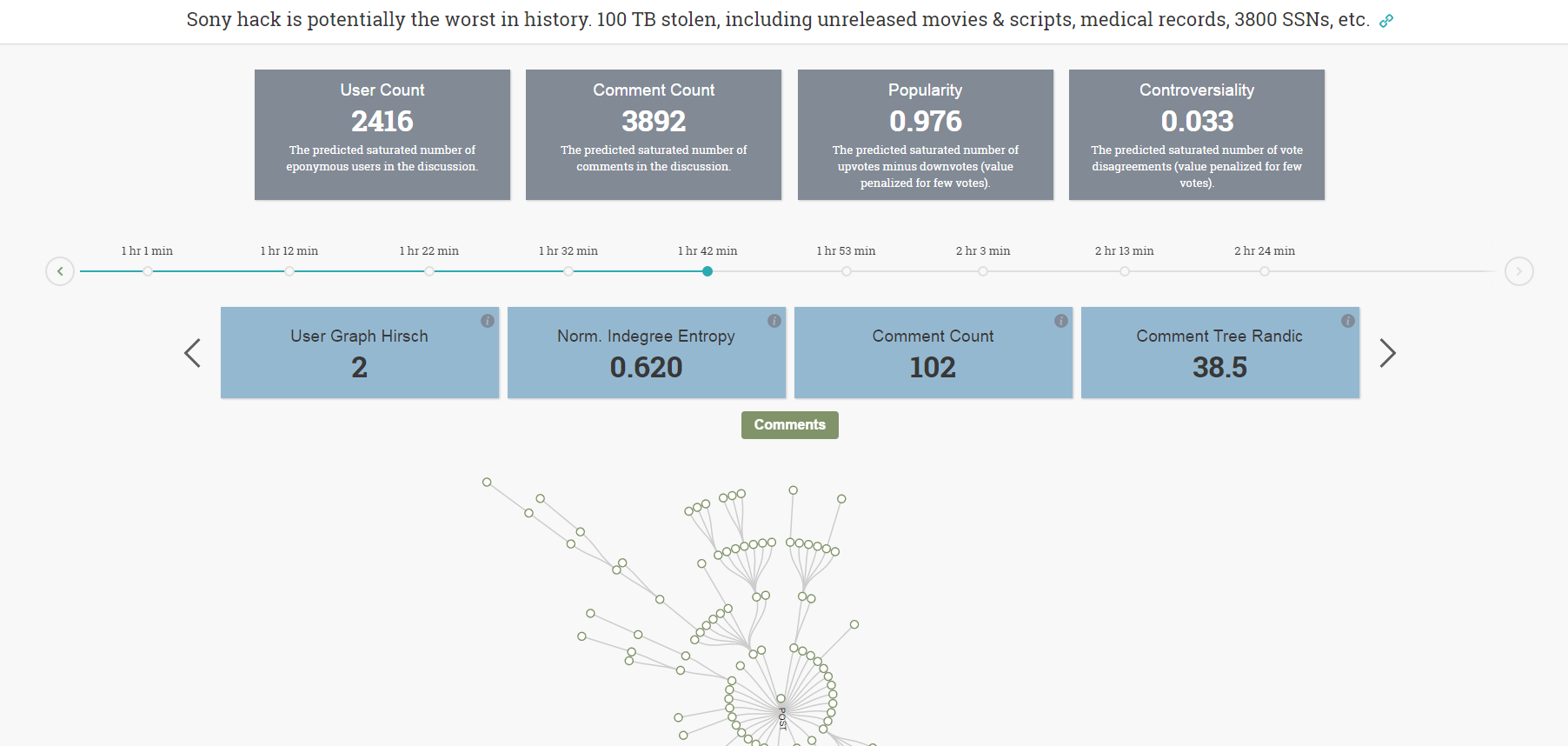
This is an algorithm that predicts the future popularity of a Reddit post or YouTube video by analyzing the comment activity under it. The algorithm builds a comment tree and a user-response graph and extracts a number of features that capture the structure of this tree and graph, which it then uses to build a predictive model. The implementation of the algorithm has been open-sourced and a public web demo is available.
DemoThis is an algorithm that classifies Twitter users to categories based on their associations with other Twitter users. The novel characteristics of the algorithm are that a) it automatically establishes the categories to categorize users by fetching and processing Twitter lists, to which a small set of Twitter(out of the set of interest) users belong, and b) the algorithm assigns categories to users both by looking into their interactions with other users and by looking into the similarities between their posts.
Learn more
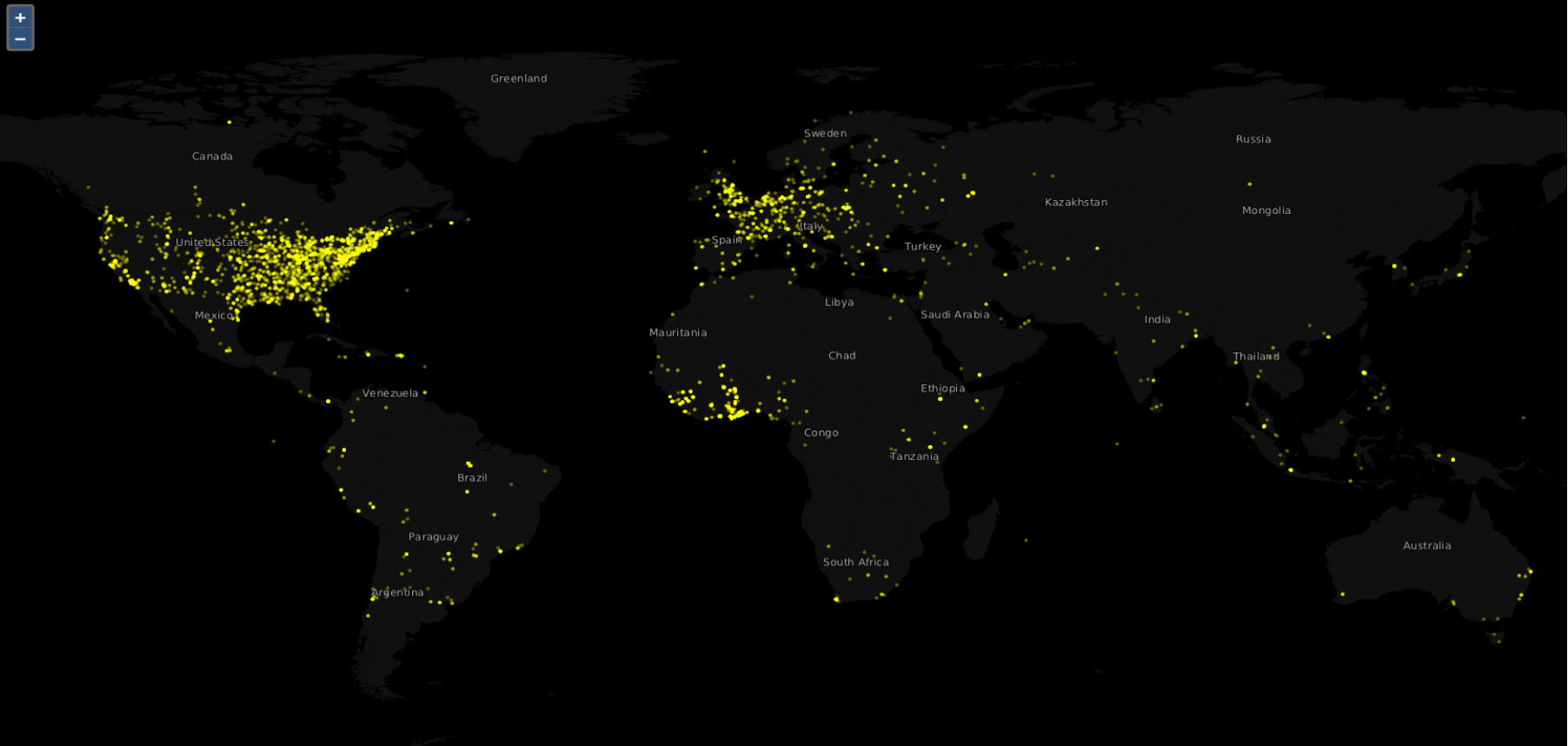
This is a highly reliable algorithm for estimating the location (in terms of latitude/longitude coordinates) of a social media post based on its text metadata (e.g. title, tags). The algorithm is based on a statistical Language Model that is “trained” on a massive set of geotagged text items from the recently released YFCC100M dataset. The algorithm also features a number of refinements, including improved feature selection and weighting, and has achieved top performance in the recent MediaEval Placing Task editions (2015, 2016). The implementation of the algorithm has been open-sourced.
This is an algorithm that analyzes a large collection of social multimedia items (i.e. posts containing images) around an event or topic of interest, and can select an appropriate subset that summarizes the main highlights of the event/topic of interest. The implementation of the algorithm has been open-sourced and made available along with two large-scale labelled datasets that can be used for evaluating its performance.