
©2024 MKLab.
Some Rights Reserved.
Built with Hugo & hyde-hyde.
Logo made by Freepik from www.flaticon.com
©2024 MKLab.
Some Rights Reserved.
Built with Hugo & hyde-hyde.
Logo made by Freepik from www.flaticon.com
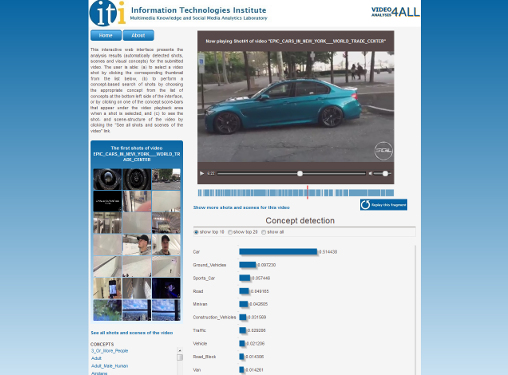
Digital images and videos are nowadays present in everyone’s life, and we are all both consumers and producers of digital audio-visual material. For us humans, it’s pretty easy to assess such visual information: just by viewing an image or a video, we can easily identify the objects and actions or events depicted in it; we get an impression of the quality of the digital medium (e.g. if a photo is blurred, it’s just obvious to us) and of the aesthetics of it (i.e., we know if it’s visually pleasing for us or not); we know if it’s something we haven’t seen before or if it’s pretty similar to a video that we saw on TV the day before; we can group the photos we took during our last trip in a way that is meaningful to us, and we can select a few of these photos to share with friends. For computers, these and other similar tasks are by no means straightforward. And, the sheer amount of image and video content that is created and communicated every minute, together with the diversity of the applications that require some form of visual information assessment (ranging from infotainment and education to security and defence applications, and from making decisions about optimal video transmission and routing in a network to supporting video recommendation, creating personalized video streams or summaries and ensuring long-term digital media preservation, to name just a few examples), make it impossible for us humans to view all the content in the world and make all the decisions. We need computers that can understand visual information just the way we do, and make related decisions for us, or help us to make these decisions. For this, we develop image and video analysis and understanding techniques that include:
and, machine learning techniques that support our analysis and understanding goals, and include:
C. Tzelepis, D. Galanopoulos, V. Mezaris, I. Patras, “Learning to detect video events from zero or very few video examples”, Image and Vision Computing Journal, Elsevier, vol. 53, pp. 35–44, Sept. 2016.
F. Markatopoulou, V. Mezaris, N. Pittaras, I. Patras, “Local Features and a Two-Layer Stacking Architecture for Semantic Concept Detection in Video”, IEEE Trans. on Emerging Topics in Computing, vol. 3, no. 2, pp. 193-204, June 2015.
P. Sidiropoulos, V. Mezaris, I. Kompatsiaris, “Video tomographs and a base detector selection strategy for improving large-scale video concept detection”, IEEE Transactions on Circuits and Systems for Video Technology, vol. 24, no. 7, pp. 1251-1264, July 2014.
N. Gkalelis, V. Mezaris, I. Kompatsiaris, T. Stathaki, “Mixture subclass discrimininant analysis link to restricted Gaussian model and other generalizations”, IEEE Transactions on Neural Networks and Learning Systems, vol. 24, no. 1, pp. 8-21, January 2013.
N. Gkalelis, V. Mezaris, I. Kompatsiaris, T. Stathaki, “Linear subclass support vector machines”, IEEE Signal Processing Letters, vol. 19, no. 9, pp. 575-578, September 2012.
P. Sidiropoulos, V. Mezaris, I. Kompatsiaris, H. Meinedo, M. Bugalho, I. Trancoso, “Temporal video segmentation to scenes using high-level audiovisual features”, IEEE Transactions on Circuits and Systems for Video Technology, vol. 21, no. 8, pp. 1163-1177, August 2011.